Improving the Performance of our Rust app
Originally published July 2021. The performance optimization techniques and architectural patterns described here continue to be fundamental to Zellij’s design and are broadly applicable to Rust application development.
During the past couple of months, we’ve been going through the process of troubleshooting and improving the performance of Zellij. During the course of our work, we found several issues and bottlenecks, and had to find some creative solutions in order to solve or get around them.
In this post I’ll describe and illustrate the two main points we’ve recently solved, which brought the app’s performance to be on par - and sometimes even exceed - that of similar apps. To learn more about Zellij and its philosophy, check out Why Zellij?.
This was a joint effort of both the Zellij maintainers and contributors from the community. Please see “Credits” below for more details.
A note about code samples
The code samples in this post are simplified versions there to illustrate the examples we’re talking about. Because Zellij is a functioning application, the actual code tends to be more involved and include details that would be confusing if included verbatim. In each code sample provided here, I also provide a link to the real world version for those who’d like to go deeper.
The “Links” section below also contains direct links to the pull requests implementing the changes discussed in this post.
Application and problem description
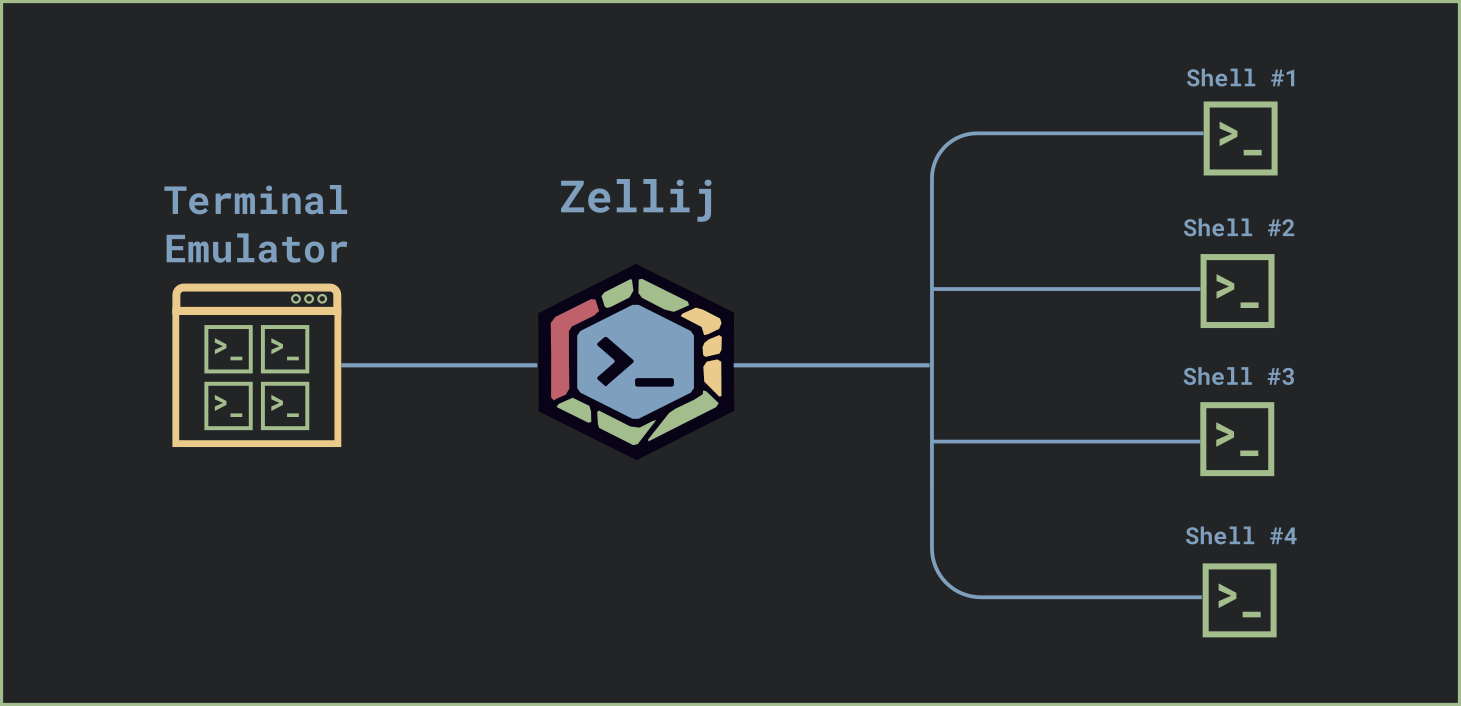
Zellij is a terminal multiplexer. In simplified terms, it’s an application running “between” your terminal emulator (eg. Alacritty, iterm2, Konsole, etc.) and shell.
It allows you to create several “tabs” and “panes”, as well as close your terminal emulator and later re-attach to the same session from a new window as long as Zellij keeps running in the background.
Zellij keeps the state of every terminal pane in order to be able to recreate it every time a user connects to an existing session, or even switches between tabs internally. This state includes the text and styling of the pane and the cursor position inside the pane.
The performance issue could be seen most strongly when displaying large amounts of data inside a Zellij pane. For example, cating a very large file. In Zellij this would be slow compared not only to a bare terminal emulator, but also compared to other terminal multiplexers.
Let’s dive in to this flow, find the performance pitfalls and talk about how we fixed them.
The problematic flow
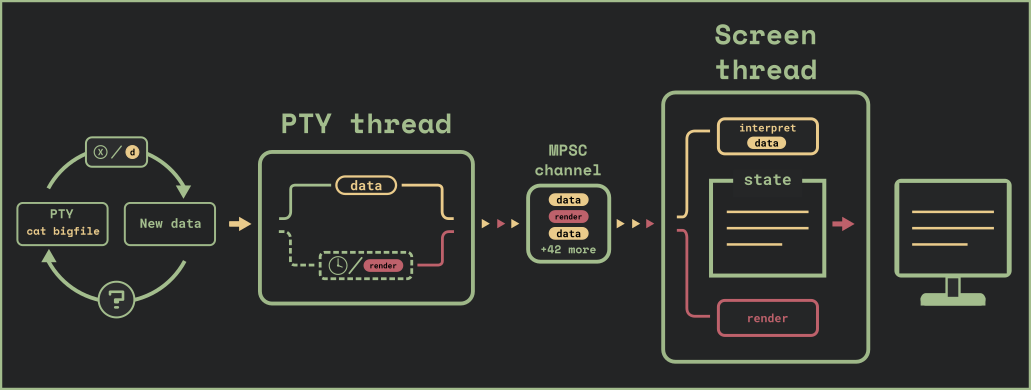
We use a multi-threaded architecture, with each main thread performing a specific task and communicating with the other thread through an MPSC channel. The data parsing and rendering flow we’re discussing includes the PTY thread and the Screen thread.
The PTY thread queries the pty which is our interface to the shell (or other program running inside the terminal), and sends the raw data to the Screen thread. That thread parses the data and builds up the internal state of the relevant terminal pane.
Once in a while, the PTY thread decides it is time to render the state of the terminal to the user’s screen and sends a render message to the screen thread.
The pty thread continuously polls the pty in order to see if it has new data in a non-blocking loop inside an async task. Sleeping a fixed amount of time if no data was received.
In addition to the data instructions it sends to the screen for parsing, it sends a render instruction if either:
- There’s no more data in the pty read buffer
- 30ms or more have passed since the last
renderinstruction was sent.
The second instance is for reasons of user experience. This is so that if there are large amounts of data streaming from the pty, the user will see them updating on their screen in real time.
Let’s look at the code:
task::spawn({
async move {
// TerminalBytes is an asynchronous stream that polls the pty
// and terminates when the pty is closed
let mut terminal_bytes = TerminalBytes::new(pid);
let mut last_render = Instant::now();
let mut pending_render = false;
let max_render_pause = Duration::from_millis(30);
while let Some(bytes) = terminal_bytes.next().await {
let receiving_data = !bytes.is_empty();
if receiving_data {
send_data_to_screen(bytes);
pending_render = true;
}
if pending_render && last_render.elapsed() > max_render_pause {
send_render_to_screen();
last_render = Instant::now();
pending_render = false;
}
if !receiving_data {
// wait a fixed amount of time before polling for more data
task::sleep(max_render_pause).await;
}
}
}
})
Here’s the real world version.
Troubleshooting the problem
In order to measure the performance of this flow, we’re going to run a cat on a file with 2,000,000 lines.
We’re going to use the excellent hyperfine benchmarking tool, making sure to use the --show-output flag in order to also measure stdout (which is what we’re concerned with).
A fair comparison would be to use tmux - a very stable and established terminal multiplexer.
The results of running hyperfine --show-output "cat /tmp/bigfile" inside tmux: (pane size: 59 lines, 104 cols)
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms]
Range (min … max): 5.526 s … 5.678 s 10 runs
The results of running hyperfine --show-output "cat /tmp/bigfile" inside Zellij: (pane size: 59 lines, 104 cols)
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms]
Range (min … max): 18.647 s … 19.803 s 10 runs
Not great! Looks like we have something to aspire to.
First problem: MPSC channel overflow
The first performance issue we have with this flow is with our MPSC channel overflowing. To visualize this, let’s speed up the previous diagram a little:
Since there’s no synchronization between the pty thread and the screen thread, the former ends up filling the MPSC channel with data much faster than the screen thread can handle it. This affects performance in a few ways:
- The channel buffer keeps growing, taking up more and more memory
- The screen thread ends up rendering more than it should, because the 30ms counter on the pty thread becomes less and less relevant as the screen thread takes more and more time to process the messages in the queue.
Solution: switch the MPSC channel to be bounded (implement backpressure)
The solution to this immediate problem is to create a synchronization between the two threads by limiting the buffer size of the MPSC channel.
To do this, we switched the asynchronous channel to a bounded synchronous channel with a relatively small buffer (50 messages). We also switched our channels to crossbeam which provided a select! macro that we found useful.
Additionally, we removed our custom asynchronous stream implementation in favor of async_std’s File to get an “async i/o” effect and not have to constantly poll in the background ourselves.
Let’s look at the changes in the code:
task::spawn({
async move {
let render_pause = Duration::from_millis(30);
let mut render_deadline = None;
let mut buf = [0u8; 65536];
// AsyncFileReader is implemented using async_std's File
let mut async_reader = AsyncFileReader::new(pid);
// "async_send_render_to_screen" and "async_send_data_to_screen"
// send to a crossbeam bounded channel
// resolving once the send is successful, meaning there is room
// for the message in the channel's buffer
loop {
// deadline_read attempts to read from async_reader or times out
// after the render_deadline has passed
match deadline_read(&mut async_reader, render_deadline, &mut buf).await {
ReadResult::Ok(0) | ReadResult::Err(_) => break, // EOF or error
ReadResult::Timeout => {
async_send_render_to_screen(bytes).await;
render_deadline = None;
}
ReadResult::Ok(n_bytes) => {
let bytes = &buf[..n_bytes];
async_send_data_to_screen(bytes).await;
render_deadline.get_or_insert(Instant::now() + render_pause);
}
}
}
}
})
And here’s the real world version.
So here is more or less what things look like afterwards:
Measuring the performance improvements
Let’s come back to our initial performance test.
Here are the numbers when running hyperfine --show-output "cat /tmp/bigfile" (pane size: 59 lines, 104 cols):
# Zellij before this fix
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms]
Range (min … max): 18.647 s … 19.803 s 10 runs
# Zellij after this fix
Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms]
Range (min … max): 9.433 s … 9.761 s 10 runs
# Tmux
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms]
Range (min … max): 5.526 s … 5.678 s 10 runs
Definitely an improvement, but looking at the numbers from Tmux we see we can still do better.
Second problem: improve the performance of rendering and data parsing
Now that we tied our pipeline to the screen thread, we should be able to make the whole thing run faster if we improve the performance of the two relevant jobs in the screen thread: parsing the data and rendering it to the user’s terminal.
Data parsing faster
The data parsing part of the screen thread has the role of taking ANSI/VT instructions (eg. \033[10;2H\033[36mHi there!) and turning them into a data structure that can be controlled by Zellij.
Here’s the relevant parts of these data structures:
struct Grid {
viewport: Vec<Row>,
cursor: Cursor,
width: usize,
height: usize,
}
struct Row {
columns: Vec<TerminalCharacter>,
}
struct Cursor {
x: usize,
y: usize
}
#[derive(Clone, Copy)]
struct TerminalCharacter {
character: char,
styles: CharacterStyles
}
The real world version can be found here and here.
Preallocating rows
While the full role of the parser and all the past and future optimizations therein are out of scope for this post, I’d like to go into a couple of optimizations that we made at this point in time that were quite significant after the pipeline improvements above.
Let’s start by looking at Row and how we add characters to it. This is one of the most frequent actions the parser performs. Especially adding characters at the end of the row.
This action mainly involves pushing those TerminalCharacters into the columns vector of the row. Each such push involves a heap allocation to resize the vector1, which is an expensive operation performance-wise. We could gain some performance by preallocating the columns vector every time we create a row or resize the terminal pane.
So we change the Row’s constructor from this:
impl Row {
pub fn new() -> Self {
Row {
columns: Vec::new(),
}
}}
}
To this:
impl Row {
pub fn new(width: usize) -> Self {
Row {
columns: Vec::with_capacity(width),
}
}}
}
Here’s the real world version.
Caching character widths
Some characters take up more space than others. Examples of such characters are East Asian letters or emoji. Zellij uses the excellent unicode-width crate to figure out the width of each character.
When adding characters to a line, a terminal emulator needs to know the current width of the line in order to decide if it should line wrap the character to the next line or not. So it needs to constantly be looking at and adding up the widths of the previous characters in the line.
Since we need to find the width of a single character many times, we could gain some speed by caching the result of calling c.width() on the TerminalCharacter struct.
So then this function (for example):
#[derive(Clone, Copy)]
struct TerminalCharacter {
character: char,
styles: CharacterStyles
}
impl Row {
pub fn width(&self) -> usize {
let mut width = 0;
for terminal_character in self.columns.iter() {
width += terminal_character.character.width();
}
width
}
}
Becomes much faster with caching as:
#[derive(Clone, Copy)]
struct TerminalCharacter {
character: char,
styles: CharacterStyles,
width: usize,
}
impl Row {
pub fn width(&self) -> usize {
let mut width = 0;
for terminal_character in self.columns.iter() {
width += terminal_character.width;
}
width
}
}
Here’s the real world version.
Rendering faster
The rendering part of the Screen thread essentially does the opposite action of the data parsing part. It takes the state of each pane, represented by the data structures described above, and turns it into ANSI/VT instructions to be sent to and interpreted by the user’s own terminal emulator.
The render loops over the viewport in the Grid, turning all the characters into ANSI/VT instructions that represent their style and location and sends them to the user’s terminal, there to replace what was previously placed there in the previous render.
fn render(&mut self) -> String {
let mut vte_output = String::new();
let mut character_styles = CharacterStyles::new();
let x = self.get_x();
let y = self.get_y();
for (line_index, line) in grid.viewport.iter().enumerate() {
vte_output.push_str(
// goto row/col and reset styles
&format!("\u{1b}[{};{}H\u{1b}[m", y + line_index + 1, x + 1)
);
for (col, t_character) in line.iter().enumerate() {
let styles_diff = character_styles
.update_and_return_diff(&t_character.styles);
if let Some(new_styles) = styles_diff {
// if this character's styles are different
// from the previous, we update the diff here
vte_output.push_str(&new_styles);
}
vte_output.push(t_character.character);
}
// we clear the character styles after each line
// in order not to leak styles from the pane to our left
character_styles.clear();
}
vte_output
}
Here’s the real world version.
Writing to STDOUT is a costly operation. We can improve our performance by limiting the amount of instructions we write to the user’s terminal.
In order to do this, we create an output buffer. This buffer essentially keeps track of the parts of the viewport that have changed since the last render. Then when we render, we cherry pick those changed parts from the Grid and send only them to stdout.
#[derive(Debug)]
pub struct CharacterChunk {
pub terminal_characters: Vec<TerminalCharacter>,
pub x: usize,
pub y: usize,
}
#[derive(Clone, Debug)]
pub struct OutputBuffer {
changed_lines: Vec<usize>, // line index
should_update_all_lines: bool,
}
impl OutputBuffer {
pub fn update_line(&mut self, line_index: usize) {
self.changed_lines.push(line_index);
}
pub fn clear(&mut self) {
self.changed_lines.clear();
}
pub fn changed_chunks_in_viewport(
&self,
viewport: &[Row],
) -> Vec<CharacterChunk> {
let mut line_changes = self.changed_lines.to_vec();
line_changes.sort_unstable();
line_changes.dedup();
let mut changed_chunks = Vec::with_capacity(line_changes.len());
for line_index in line_changes {
let mut terminal_characters: Vec<TerminalCharacter> = viewport
.get(line_index).unwrap().columns
.iter()
.copied()
.collect();
changed_chunks.push(CharacterChunk {
x: 0,
y: line_index,
terminal_characters,
});
}
changed_chunks
}
}}
Here’s the real world version.
The current implementation only deals with full line changes. It can be further optimized to only send the part or parts of a line that changed, but when attempting that I found that it increases the complexity significantly without providing a very significant gain in performance.
So, let’s look at the performance we’ve gained after all these improvements:
The results of running hyperfine --show-output "cat /tmp/bigfile" after the fixes: (pane size: 59 lines, 104 cols)
# Zellij before all fixes
Time (mean ± σ): 19.175 s ± 0.347 s [User: 4.5 ms, System: 2754.7 ms]
Range (min … max): 18.647 s … 19.803 s 10 runs
# Zellij after the first fix
Time (mean ± σ): 9.658 s ± 0.095 s [User: 2.2 ms, System: 2426.2 ms]
Range (min … max): 9.433 s … 9.761 s 10 runs
# Zellij after the second fix (includes both fixes)
Time (mean ± σ): 5.270 s ± 0.027 s [User: 2.6 ms, System: 2388.7 ms]
Range (min … max): 5.220 s … 5.299 s 10 runs
# Tmux
Time (mean ± σ): 5.593 s ± 0.055 s [User: 1.3 ms, System: 2260.6 ms]
Range (min … max): 5.526 s … 5.678 s 10 runs
And here we have it. This puts us on par with existing and established terminal multiplexers, and while there’s definitely still room for improvement, it provides for quite a decent and pleasant user experience.
Conclusion
The test we used to measure performance, cating a big file, only measures performance in a very specific circumstance. There are other scenarios in which the performance of Zellij lacks or shines. It’s also important to note that because we are measuring the performance of full apps in a relatively complex and not 100% sterile environment, the measurements in this post should be regarded as loose signposts rather than exact measurements.
Zellij does not claim to be faster or more performant than any other software. Performance-wise, it only uses other software as an inspiration and something to aspire to.
If you found any error in this post, would like to offer a correction, your ideas, or feedback - feel free to reach out to aram@poor.dev.
Thank you for reading.
Links
- First PR of the backpressure implementation
- Second PR of the backpressure implementation
- The PR improving the data and render performance
Credits
- Tamás Kovács - for troubleshooting the MPSC channel overflow and implementing the backpressure, as well as reviewing this post
- Kunal Mohan - for reviewing and helping to integrate the backpressure implementation, as well as reviewing this post
- Aram Drevekenin - for troubleshooting and implementing the data/render improvements
-
As pointed out on Reddit by luminousrhinoceros, this is not 100% accurate. A
Vecdoubles its capacity whenever one pushes an element that exceeds its current capacity. Still a costly operation, but not one that happens on every single push. ↩︎